My perfect AWS and Kubernetes role-based access control and the reality

…or our problems with IAM, Kubernetes RBAC, and how we tried to solve them.
When I wanted to create the role-based access control for DevOpsBox I had a clear vision of what I want to achieve and… I had a clash with the reality of AWS IAM, Kubernetes RBAC, and to a lesser extent with Keycloak. In this article, I want to describe some of my problems and how we solved (or worked around) them.
For those of you who don’t have enough time to read the whole story I will list all the problems we encountered:
Kubernetes/EKS RBAC
- It is not possible to provide a resource name for the create (or deletecollection) operation.
- You cannot use any regexp when using a resource name, you can only use the exact name.
- When writing a Kubernetes operator, you do not have any information in your controller code about who created the resource.
- You must add read/write permissions for all the secrets in a namespace if you want to use Helm 3 default release information store (HELM_DRIVER=secret).
- In EKS, if you grant permission to modify any configmap (cluster role without any resource name), it means you also allow to modify the aws-auth configmap in the kube-system namespace, so the user can add himself to the “system:masters” group.
AWS IAM
- With IAM you grant permissions to the AWS API, so it is too fragmented and the policies are getting very big and hard to write and maintain.
- Not all the resources support ABAC (permissions based on tags).
- There are a lot of operations that do not allow restricting permissions to resource names.
- There is a limit for the policy length and the number of policies assigned to an IAM Role.
Keycloak
- You cannot filter roles in the UI when you are assigning them to a user or a group.
Our dreams
These were my requirements:
- I wanted our users to have the possibility to grant permissions per combination of an application (or microservice) and its environment.
- Some permissions are non-environment-specific (e.g. build) — it should be possible to grant them separately.
- It should be possible to have different permissions for deployment with resources (cloud or containers) creation and one that only changes the application’s version. This separation allows us to have “power users”, who know what they do when they change cloud resources and are also responsible for controlling cloud costs.
- The deployment through CI/CD should use the user’s cloud and Kubernetes permissions (this is the hardest one…).
- A user should not have permissions to anything more than what he has been granted. For example, if he can create the deployment Kubernetes resource for one application, it does not mean that he can do it for another one or in a different environment.
- We wanted to have namespace per environment in our Kubernetes clusters. This was our assumption before we started to implement access control.
- We should have separate permissions for viewing application data (including logs). This one should help to be GDPR compliant.
- Of course, everything should be as clear and simple as possible.
After discussions, we ended up with these permissions’ list (the list is for a hypothetical application named “Orders”, which has dev and prod environments):
It can be extended in the future
The full deployment process through CI/CD should look like this:
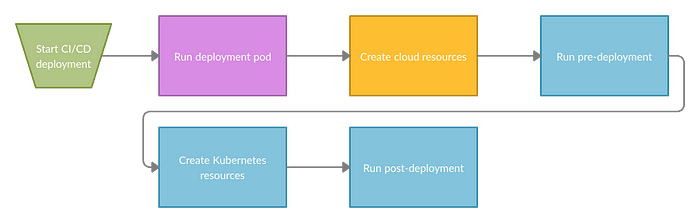
- User “clicks” deploy on an environment of some application and the process starts.
- The deployment pod starts and the following steps are run in this pod (does not run on CI/CD server and allows us to have better scalability).
- Cloud resources are created using the user’s permissions (IAM policy).
- The pre-deployment pod is executed and runs to the end. It can be used for example to run the database migration. It should also be run on the user’s permissions (Kubernetes RBAC).
- Kubernetes resources should be created. Here we create lots of resources, a few of them are deployment, service, horizontal pod autoscaler, Istio virtual service. Of course, this step should use user’s permissions (Kubernetes RBAC)
- The post-deployment pod is executed and runs to the end. You can use it to do some configuration after the application deployment. Again, it should run on the user’s permissions.
We thought that our ideas were great, and then we woke up…
The reality
The problem is that almost all of my requirements were impossible to implement. I will go through our “perfect process” and show you how we implemented it or changed our requirements. Then, I will write about AWS and Kubernetes users’ permissions. There is also one problem with Keycloak, which I will also describe.
Run the deployment in CI/CD
Here everything is almost as it should be.
The “only” problem is that it is not easy to run the pipeline on the user’s credentials. It runs on CI/CD server credentials (Kubernetes service account), but we know who started the process, and we can allow CI/CD to impersonate the user. Everything is autogenerated, and we do not allow users to modify the pipelines, so this should be secure enough.
Starting the deployment pod
So we have impersonated our user, and we want to start the deployment pod on his/her permissions. Here we are, actually, allowing our user to create any pod in some namespace. It is impossible to restrict the resource name for the create verb! And even if it was possible you can’t use any kind of regexp, or something in the resource name field (https://github.com/kubernetes/kubernetes/issues/56582). Permission to start any pod will allow you to read any secret in this namespace, assign any service account, and execute lots of not so secure things…
After some research, we decided to create our own Kubernetes operators (one for the build and one for the deployment). It turns out that it is not that hard, but it is easiest to do it in Golang, and we had no skills in this language. Even so, we decided to go for it. We tried both operator-sdk and kubebuilder, and we chose kubebuilder, but we are using our Helm chart instead of kustomize (which is the default).
We have defined the following custom resources:
- BoxFullDeployment,
- BoxAppDeployment,
- BoxFullUndeployment,
- BoxStart,
- BoxStop,
- BoxBuild
We will probably extend the list in the future.
Is having our own operator enough to allow us to restrict permissions using resource names? No, it is not! You can’t restrict it for the create verb! But at least, we do not allow the creation of any pod…
If we cannot use resource names, then what can we do? Split Kubernetes namespaces per application’s environment. For our hypothetical Orders application we will have the following namespaces:
- dev-orders
- prod-orders
It was quite a hard decision to have so fragmented namespaces, but it turns out that it is not that bad. The only drawback is the less convenient use of kubectl.
One more problem — who and when creates these namespaces? We run the namespace creation in a CronJob. We also create roles and role bindings in Kubernetes based on Keycloak groups and their permissions in the same CrobJob.
Cloud resources are created from the deployment pod using users’ credentials
We had lots of problems here. First of all, we have no bloody idea who has created a resource in Kubernetes (https://github.com/kubernetes/kubernetes/issues/13306), so we gave up the idea of running everything on the user’s permissions. Luckily, after consideration, it should be enough to have operators and grant permissions to our custom resources.
Ok, but if we are creating cloud resources from the deployment pod, should the Kubernetes node (and any application running on it) be allowed to create those resources? Here we can use IAM roles for service accounts, so our deployment pod has a specific IAM role assigned (I will write a separate article about EKS and IAM integration and paste a link here when it is ready).
The pre-deployment pod starts on the user’s permissions
Same problems as when creating cloud resources, but related to Kubernetes. The solution was almost the same. The only difference is that we are granting Kubernetes RBAC permissions to the deployment’s pod service account.
Kubernetes resources should be created.
I noticed one more problem here. We use Helm 3 to manage resource creation/deletion. We do not use the templating feature as we generate ready to use yamls. The problem with Helm is that it stores its metadata in secrets, and their names change on every deployment/upgrade. It means that if you want to grant the user to do only “helm ls” you have to grant him/her to read all the secrets in the namespace! I have reported an issue on Helm’s GitHub (https://github.com/helm/helm/issues/8122), but maybe my description was not clear enough and they closed it. Luckily, you can use HELM_DRIVER=configmap, it is much more secure to let users read all the configmaps than the secrets… but what if you use a third-party Helm chart and you don’t know if it contains any sensitive data? We use configmap for our charts (those generated) and secrets for the third party charts.
The post-deployment
The same as pre-deployment
AWS user permissions
We gave up using user’s permissions for the deployment process, but we still wanted to grant AWS permissions for the Console, CLI, or API usage. Permissions should still be granted per the combination of an application and its environment. We have written a lambda function that generates an IAM role for every Keycloak group using AWS CDK (My article about running CDK from Lambda: https://raszpel.medium.com/running-aws-cdk-from-a-lambda-function-9369d3daba57).
First, we looked at ABAC — it is really promising and could solve our problems in quite an elegant way. However, there are a few issues with ABAC:
- Not all AWS Services supports ABAC. S3 does not have the full support to name one (look at “Authorization based on tags” in https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_aws-services-that-work-with-iam.html). So we decided to use tags for services that support them, and resource names for services that do not support tags.
- Even if a Service supports ABAC, there are still some operations that cannot be restricted by tag (or even a resource name). For example, if you do not have rds:DescribeDBInstances for all RDS instances, you cannot view any instance on the list in the AWS Console. We decided to carefully grant permissions for all resources when it is not too dangerous.
- The condition language is quite limited. If you want to grant permissions for the application named Orders on dev and staging environments and the application Customers only on the dev environment, you will have to repeat the whole policy statement e.g.:
{
"Condition": {
"StringEquals": {
"aws:ResourceTag/BoxAppName": [
"Orders",
"Customers"
],
"aws:ResourceTag/BoxEnvironment": "dev"
}
},
"Action": [
"rds:Describe*",
"rds:List*"
],
"Resource": "*",
"Effect": "Allow"
},
{
"Condition": {
"StringEquals": {
"aws:ResourceTag/BoxAppName": [
"Orders"
],
"aws:ResourceTag/BoxEnvironment": "staging"
}
},
"Action": [
"rds:Describe*",
"rds:List*"
],
"Resource": "*",
"Effect": "Allow"
}There are more issues related to IaM:
- The fragmentation of IAM permissions is very high (per every API operation), so it is quite hard to write policies, and they are getting really big. When writing the policies, we used two techniques: checking in Cloud trail (but you have to wait a few minutes for the data) and checking HTTP requests in chrome or firefox dev console. It is often quite easy to read what the problem was from the HTTP path, request, or response body. TIP: not all access denied responses have the status 403, some of them have even 200 and you have to analyze them more deeply.
- You can hit the limit when policies are even bigger. You can read here https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_iam-quotas.html that: “Role policy size cannot exceed 10,240 characters”, “The size of each managed policy cannot exceed 6,144 characters.”, “You can add up to 10 managed policies to an IAM user, role, or group.” and “IAM does not count white space when calculating the size of a policy against these quotas.”. We haven’t solved the problem yet, but when we hit the limit, we will write some code to split our policies into smaller chunks. Luckily, our policy generator is written in Java, so it shouldn’t be that hard to write that code and unit test it.
- You will need some naming convention and a mechanism to avoid collisions when using resource names. For example, our policy for s3 can look like this:
{
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": [
"arn:aws:s3:::dev-orders-*",
"arn:aws:s3:::dev-customers-*",
"arn:aws:s3:::staging-orders-*"
],
"Effect": "Allow"
}And we are aware that somebody can name his application “orders-whatever” and all the users having permissions for orders will see his buckets. ABAC is much better… We will write some code to notify our users that such a collision exists and it is not allowed.
Kubernetes permissions
After switching to namespace per application and environment approach, it wasn’t that hard to create the solution for Kubernetes. We have a CronJob in each cluster, which reads Keycloak groups, adds mappings to aws-auth config map in kube-system namespace, and then, creates appropriate roles and role bindings based on roles granted to Keycloak groups. There is one thing worth mentioning here:
In EKS, if you grant permission to modify any configmap (cluster role without any resource name), it means you also allow to modify the aws-auth configmap in the kube-system namespace, so the user can add himself to the “system:masters” group.
Keycloak
We use Keycloak for our platform tools SSO (but it is not required for applications deployed on our platform). We very like the way it is designed, there are roles, groups, clients, composite roles, etc. But when we started to create our solution, we thought that we will have realm roles for each application/environment. The list will grow quite fast and it is not possible to filter roles when assigning to a group or user. We decided to create a Keycloak client per application to group its roles, so the list is manageable, and it is also possible to filter client names.
Conclusion
Here is our final deployment process:
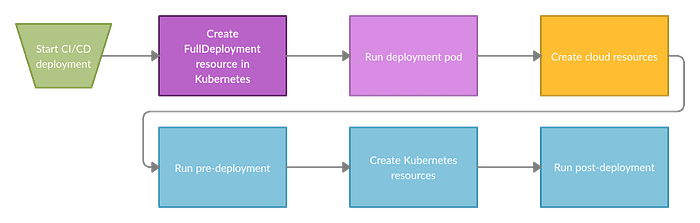
As you can see, we use a combination of multiple techniques to achieve almost what we wanted. If you think that I am wrong somewhere in this article all know how to do it simpler, please leave a comment or contact me on LinkedIn (https://www.linkedin.com/in/maciejraszplewicz/).
For more details about the DevOpsBox platform please visit https://www.devopsbox.io/
